
롯데호텔 채널시스템 리뉴얼
프로젝트 개요
롯데호텔 시그니엘 및 글로벌 체인(30개) 채널 재구축 및 예약/회원 고도화 및 디자인 리뉴얼 프로젝트입니다. 기존 시스템의 화이트 페이지 이슈 해결과 페이지 전환 속도 개선을 최우선 목표로 진행되었습니다.
프로젝트 아키텍처 설계, 애플리케이션 빌드/배포, 공통 모듈 및 컴포넌트 설계, 모바일 앱·웹뷰 브릿지 함수 설계, 개발표준 정의서 및 컴포넌트 명세서 작성/교육 등을 담당했습니다.
목차
- 대규모 글로벌 서비스의 CSR/SPA 렌더링 최적화 및 아키텍처 개선
- 검색엔진 최적화(SEO)와 prerendering
- 아키텍처에 대한 고민과 FSD 적용
- 캐싱 및 서버 상태 관리 도입
- 공통 컴포넌트 가이드 및 Storybook 기반 CDD 환경 구축
1. 대규모 글로벌 서비스의 CSR/SPA 렌더링 최적화 및 아키텍처 개선
문제 상황
- 초기 렌더링 속도 저하: 글로벌 30개 체인의 방대한 콘텐츠를 다루다 보니, CSR/SPA 환경에서는 번들 크기가 커져 초기 로딩이 지연되었습니다.
- 화면 전환 시 UX 저하: 페이지 Lazy Loading을 적용하면서 라우트 이동 시 잠깐씩 화면이 하얗게 비는 현상(화이트 페이지)이 자주 노출되었습니다.
- 배포 시 캐싱 및 청크 에러: 자주 배포하다 보니, 구버전 캐시가 유지되어 리소스가 충돌하거나, 새 버전 배포 시 청크 로드 에러가 발생할 가능성이 높았습니다.
해결방안
저는 사용자가 3초 이내에 초기 화면에 진입할 수 있도록 하고, 화면 전환 시 화이트 페이지가 보이지 않도록 아키텍처를 전면적으로 개선하고 렌더링 방식을 최적화했습니다.
1) IA 기반 라우트 구조 설계 및 RouteObject 선언적 관리
- 최상위 레벨을 체인/글로벌/아라이 세 가지로 나누고, URI 체계에 맞춰 하위 디렉터리 구조를 통일했습니다. 불필요한 디렉터리 깊이 대신 "_" 패턴을 활용하여 구조를 단순화했습니다.
<Route />대신RouteObject[]를 도입해 라우트 설정과 View를 분리하고, 독립적인 라우트 관리 환경을 구축했습니다.- Vite의 동적 import 경로 제약을 해결하기 위해, pages 계층을 기준으로 올바른 상대 경로를 반환하는 전용 헬퍼 함수를 직접 구현해 개발자 경험(DX)을 크게 향상시켰습니다.
2) UX 향상을 위한 Custom Preloading 구현
- Next.js의 Prefetching 방식을 참고해, 링크에 마우스를 올리면 해당 페이지의 청크를 미리 로드하는 전용 Link 컴포넌트와 usePreload 훅을 개발했습니다.
- 이 서비스는 경로 뎁스가 1~4단계로 얕은 특성을 갖고 있어, 라우트 객체를 재귀적으로 탐색해 관련 컴포넌트를 로드하는 구조로 최적화가 가능했습니다.
3) 리소스 최적화 및 에러 핸들링 자동화
- 인프라팀과 긴밀히 협업하여 CloudFront 캐싱 정책을 수립했고, Vite 빌드 과정에서는 terser로 번들 파일을 압축해 리소스 용량을 줄였습니다.
- vite-plugin-html을 통해 빌드 타임스탬프를 외부 리소스 쿼리스트링에 삽입해, 매번 배포 시 캐시가 자동으로 갱신되도록 했습니다.
- 또한 Vite의 vite:preloadError 이벤트를 감지하여, 이전 버전 청크 로드 실패 시 페이지를 자동 새로고침하도록 에러 핸들링 로직을 추가해 서비스 중단 없이 최신 환경으로 전환할 수 있게 했습니다.
위 방법을 채택한 배경과 이유
-
라우트 구조와 RouteObject
수백 개의 라우트가 존재하는 구조에서, 파일 조직의 일관성을 확보해야 manualChunks 같은 번들링 최적화가 수월해집니다. 또한 담당 영역을 명확히 분리함으로써 협업 시 코드 충돌을 방지하고, 향후 데이터 prefetching 확장까지 고려하면 가장 안정적인 아키텍처였다고 생각합니다.
-
Custom Preloading & 재귀 탐색
CSR/SPA에서 자주 경험하는 화면 전환 지연 문제를 반드시 해결하고 싶었습니다. 뎁스가 얕은 서비스 구조 덕분에 재귀 탐색의 성능 부담이 적었고, 가독성과 유지보수성 모두를 고려해 이 방식을 채택했습니다.
-
캐시 버스팅과 에러 핸들링 자동화
인프라의 캐싱 이점을 최대한 살리면서도, 사용자에게 항상 최신 버전을 제공하고자 했습니다. 배포 과정 중 '화면 멈춤'을 방지하고 자연스럽게 새로고침이 이루어지도록 설계해 서비스 안정성과 UX를 동시에 잡을 수 있었습니다.
성과 및 기대 효과
아키텍처 재설계와 렌더링 최적화를 통해 성능, 사용자 경험(UX), 그리고 개발 생산성 측면에서 뚜렷한 성과를 거둘 수 있었습니다.
-
초기 렌더링 속도 최적화
체계적인 코드 스플리팅과 번들 압축, CloudFront 캐싱 전략을 적극적으로 적용한 결과, 프로젝트 초기 목표였던 3초를 넘어, 실측 기준 FCP가 2.7초 이내로 개선되었습니다.
-
화면 전환 시 대기 시간 최소화 및 화이트 페이지 제거
Hover 기반의 커스텀 프리로딩을 도입해 화면 전환 속도 대폭 향상함으로써 라우트 이동 시 발생하던 화이트 페이지 현상을 해결했습니다.
-
안정적인 배포 환경 구축 및 사용자 이탈률 방지
캐시 버스팅 자동화와 자동 리로드 로직을 적용해 빈번한 무중단 배포 상황에서도 Chunk Load Error로 인한 화면 오류 발생률을 0%로 유지, 사용자에게 끊김 없는 서비스를 제공할 수 있었습니다.
-
대규모 협업 환경에서의 개발 생산성 향상
수백 개의 라우트를 IA 기반으로 구조화함으로써 여러 프론트엔드 개발자가 동시에 작업해도 코드 충돌 없이 효율적으로 협업할 수 있게 했으며, 유지보수성 역시 큰 폭으로 개선했습니다.
아쉬웠던 점 및 보완 방향
- 모바일 환경에서의 프리로딩 한계: 현재 프리로딩이 마우스 호버에만 반응하다 보니, 터치 기반의 모바일 환경에서는 효과가 제한적입니다. 향후 Intersection Observer를 활용해, 링크가 화면에 보이거나 사용자가 터치 시작할 때 프리로딩이 트리거되도록 로직을 개선할 계획입니다.
- 정교한 캐시 무효화 전략: 타임스탬프로 쿼리스트링을 일괄 갱신하는 방식은 확실하게 캐시를 비우긴 하지만, 실제로 변경되지 않은 리소스까지 모두 대상이 된다는 단점이 있습니다. 앞으로는 번들러의 콘텐츠 해시(Content Hash)를 외부 정적 파일과도 완전히 연동하는 방법으로 개선해, 더 효율적이고 신뢰할 수 있는 캐시 관리 전략을 갖추고자 합니다.
2. 검색엔진 최적화(SEO)와 prerendering
문제 상황
- 인프라 제약과 일정 문제: SEO팀의 권고대로 SSR(Next.js) 적용을 검토했지만, 기존 AWS S3 정적 호스팅 환경을 포기하고 EKS 등으로 인프라를 완전히 갈아엎어야 했습니다. 단순히 인프라만 바뀌는 것이 아니라, 비용도 눈덩이처럼 불었고, 내부 팀원들의 학습 부담까지 고려하면 정해진 론칭 일정에 맞추는 것은 사실상 불가능에 가까웠습니다.
- 대규모 페이지 빌드의 병목: 페이지가 약 10,000개에 이르다 보니, 하나씩 차례대로 크롤링·렌더링하는 작업에서 병목이 심하게 발생했습니다. 단일 스레드로 돌릴 경우, 1,000페이지를 생성하는 데만 네 시간가량 걸렸습니다. 이로 인해 Jenkins 파이프라인의 최대 허용 시간(9시간)을 종종 초과했고, 결국 정적 HTML 배포가 실패하는 사례가 빈번했습니다.
- CDN 레벨에서의 분기 처리 한계: 접근 권한의 제약으로 인해 CDN 구간에서 일반 사용자와 검색엔진 봇을 구분해 라우팅하는 설정도 적용할 수 없었습니다. 결국 트래픽 분기나 SEO 대응이 인프라 측면에서 막혀 있었던 셈입니다.
해결 방안
저는 기존 S3 인프라와 React 개발 체계를 최대한 건드리지 않으면서, SEO 요구 조건을 충족할 수 있는 Prerendering 기반 정적 HTML 생성 및 크롤링 자동화 워크플로를 설계하고 직접 구축했습니다.
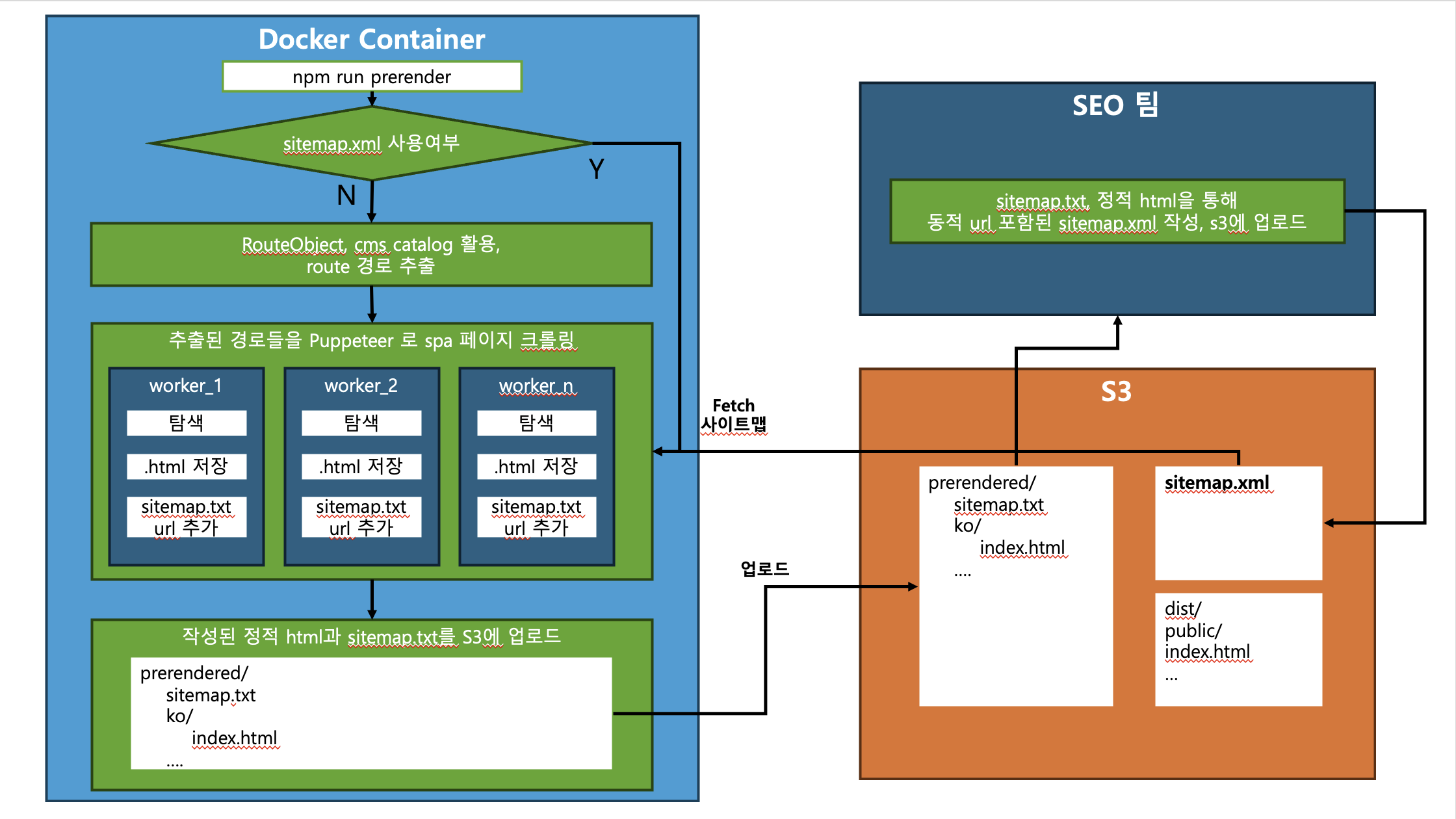
1) React 레벨의 동적 SEO 및 Puppeteer 스냅샷 동기화
- CMS 데이터를 기반으로 title, description, og-tag 등 다양한 메타 태그를 동적으로 렌더링했습니다.
- CMS에서 내려온 데이터가 없을 시, SEO 가이드라인에 따라 특정 텍스트 클래스(.first-txt01 등)에 우선순위를 매겨 메타데이터가 자동으로 반영되도록 커스터마이즈 했습니다.
- Puppeteer가 페이지를 크롤링할 때는 데이터 페칭과 렌더링이 완전히 끝났는지 공통 DOM 셀렉터로
Await해, 정보 누락이나 빈 페이지가 생기지 않도록 방지했습니다.
2) 병렬 처리로 Prerendering 프로세스 최적화
- 심각한 렌더링 병목 문제를 해결하고자, 커뮤니티 신뢰도가 높은 puppeteer-cluster 라이브러리를 활용해 워커(Worker) 기반 병렬 처리 환경을 만들었습니다.
- 시스템 메모리 초과(OOM)를 예방하고 안정을 보장하기 위해 전체 CPU 코어의 약 75%만 병렬 처리에 사용하고, 나머지 25%는 운영체제와 Node.js 이벤트루프, 가비지 컬렉터가 원활히 동작할 수 있도록 남겼습니다.
- 각 워커와 작업 별로 난수 ID를 부여해 로그 추적과 디버깅을 용이하게 하고, 전체 모니터링 체계를 갖췄습니다.
3) 객체지향 설계 및 LSP 적용
- 복잡한 Prerendering 스크립트를 객체지향적으로 설계하여 모듈간 의존성을 낮추고 코드의 응집도를 높였습니다.
- 리스코프 치환 원칙을 적용해 IRouteProcessor 인터페이스를 별도로 정의함으로써 크롤링 대상 경로가 Route 또는 sitemap.xml 기반으로 변동에 용이하도록 했습니다.
4) User-Agent 기반 라우팅과 Canonical Tag 활용
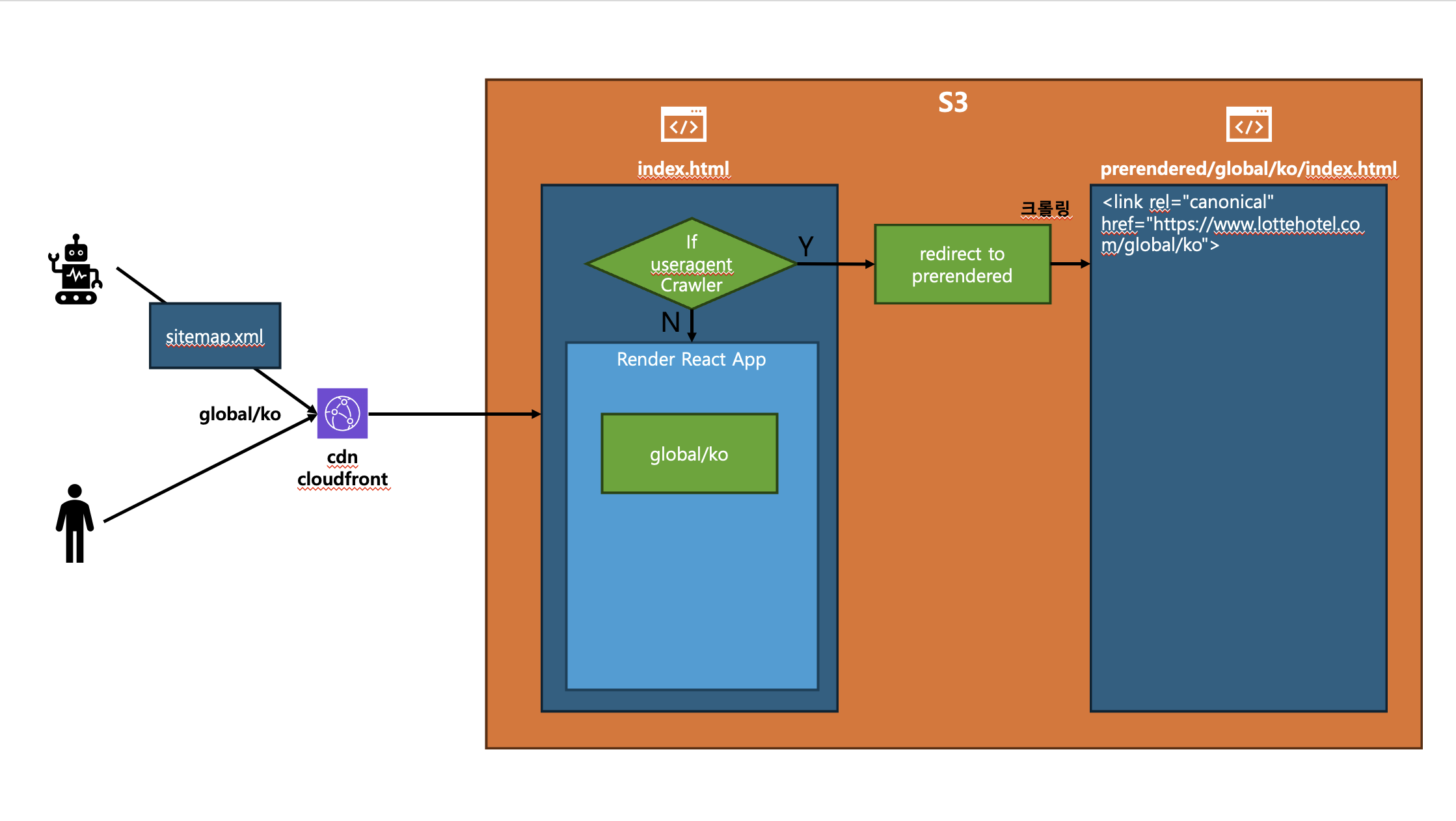
- CDN에서의 제약을 우회하기 위해, 클라이언트 진입점에서 User-Agent 값을 분기해 검색엔진 봇에게만 Prerendering된 정적 HTML을 제공하는 전략을 적용했습니다.
- 원본 URL과 정적 HTML 경로가 다를 때 중복 콘텐츠 패널티 이슈를 막기 위해서, 모든 페이지에 원본 URL을 가리키는 Canonical Tag(
<link rel="canonical"/>)를 자동으로 삽입해 검색엔진이 올바른 URL로 인식할 수 있도록 하였습니다.
위 방법을 채택한 배경과 이유
- Prerendering 전략 채택: 새로운 프레임워크(Next.js)를 도입해 SSR을 구현하려면 예상 밖의 인프라 투자와 개발 리소스가 필요했습니다. 이로 인한 시간·비용 부담, 그리고 팀원들의 러닝커브 문제를 감안할 때, 기존 환경을 유지하면서 단기간 내 SEO 요구를 충족할 수 있는 가장 현실적이고 효율적인 해결책이 바로 Prerendering이었습니다.
- 코어 75% 점유율 병렬 처리: 처음에는 시스템 자원을 100% 활용해 성능을 극대화하고자 했지만, 오히려 메모리 부족(OOM)으로 워커가 비정상 종료되는 현상이 잦았습니다. 실제로 대규모 크롤링 환경에서는 가비지 컬렉션 및 기본 시스템 동작을 위한 25%의 자원을 남기는 것이 프로세스 안정성을 높이는 밸런스임을 직접 경험을 통해 확인했습니다.
- 객체지향적 설계와 LSP 적용: 복잡한 코드의 가독성 향상을 위해 역할과 책임을 분명히 하는 객체지향적 설계를 적용했습니다. 또한 프로젝트 론칭 초기에는 Route 기반으로, 안정화 이후에는 sitemap.xml 기반으로 크롤링 대상을 수시로 교체해야 하는 요구사항이 있었습니다. 핵심 로직의 수정 없이 크롤링 전략만 유연하게 교체할 수 있도록 했습니다.
- User-Agent 기반 우회와 Canonical Tag 주입: CDN에서 봇 분기 처리가 불가능한 환경에서 어쩔 수 없는 선택이었습니다. 하지만 SEO 페널티(중복 콘텐츠) 문제까지 꼼꼼하게 고려해 Canonical Tag를 자동 주입함으로써, 서비스의 검색엔진 노출 안정성을 한층 높일 수 있었습니다.
성과 및 기대 효과
제한된 인프라 환경에서도 아키텍처의 유연성을 살리고 병렬 처리 최적화를 이루어, Prerendering 안정성과 SEO 성능을 동시에 확보할 수 있었습니다.
-
빌드 속도 혁신과 파이프라인 안정화
병렬화된 처리 방식을 적용하면서도 메모리 오버플로우를 방지해, Jenkins 제한 시간 내에 안정적인 배포를 이뤄낼 수 있었습니다. 이로써 CI/CD 파이프라인의 신뢰도가 한층 높아졌습니다.
-
비용 절감과 검색 노출의 극대화
기존 인프라(S3)를 그대로 활용함으로써, 추가 서버 구축이나 운영에 드는 큰 비용을 막아낼 수 있었습니다. 또한, 검색엔진 봇이 완전히 렌더링된 메타데이터를 정상적으로 파싱할 수 있게 되어, 글로벌 웹사이트의 SEO 품질도 크게 향상되었습니다.
-
약 8배에 달하는 성능 향상
1,000개 페이지 크롤링에 소요되던 시간이 약 4시간에서 30분 안팎으로 대폭 단축되는 성과를 거두었습니다.
아쉬웠던 점 및 보완 방향
크롤링 전략을 변경할 때 운영의 유연성이 부족했던 점이 아쉬웠습니다. 비록 객체지향 설계 원칙을 적용하여 구조를 유연하게 설계했지만, 크롤링 소스(Route와 Sitemap)를 바꿀 때마다 반드시 코드를 수정하고 재배포하는 절차를 거쳐야 했기 때문입니다.
앞으로는 CLI 환경 변수나 실행 시점을 활용해 전략 설정을 동적으로 주입받는 방식을 도입할 계획입니다. 이를 통해 코드 수정과 재배포 없이도 손쉽게 운영 전략을 조정할 수 있어, 개발자 경험 또한 한 단계 더 높아질 것으로 기대합니다.
3. 아키텍처에 대한 고민과 FSD 적용
문제 상황
기존에 사용하던 역할 기반 디렉토리 구조(views, components, hooks 등)는 소규모 프로젝트에서는 무리 없이 운영할 수 있었습니다. 그러나 프로젝트 규모가 커지면서 몇 가지 뚜렷한 한계점이 드러났습니다.
- 파일 탐색 비용의 증가: 하나의 폴더 내에 수십, 수백 개의 파일이 쌓이다 보니, 파일명을 정확히 기억하지 않으면 원하는 코드를 찾기까지 꽤 많은 시간을 허비하곤 했습니다.
- 비즈니스 도메인 단위로의 응집도 부족: 서로 다른 비즈니스 영역의 코드가 한 공간에 뒤섞여 있어, 특정 기능을 수정하거나 구조를 파악해야 할 때 관련 파일을 하나하나 뒤져야 하는 번거로움이 있었습니다.
- 역할과 책임의 모호성: 전역 설정, 레이아웃, 재사용 모듈 등 다양한 성격의 코드가 명확한 기준 없이 공존하다 보니, 디렉토리 구조만으로는 각 코드의 성격이나 의존성을 파악하기 어려웠던 것이 사실입니다.
해결방안
단순히 폴더를 재정리하는 것을 넘어, 각 요소의 '역할', '의존성', '변경 가능성'까지 체계적으로 관리하고자 사내 프론트엔드 표준으로 FSD(Feature-Sliced-Design) 아키텍처를 도입하였습니다.
1) 계층 및 도메인 분리 적용
- app → pages → widgets → features → entities → shared 순으로 단방향 의존성을 갖는 계층 구조를 정립했고, 각 계층 내부는 비즈니스 도메인(slice), 혹은 기능(segment) 단위로 세분화해 관리했습니다.
2) 백엔드 개발자를 위한 레이어 매핑
- React 경험이 부족한 팀원들이 구조를 쉽게 이해할 수 있도록 pages는 Controller, features는 Service, entities는 DTO 등으로 백엔드 개념과 연계한 매핑 가이드를 제공하였습니다.
3) 프레임워크 종속성 최소화
- 프레임워크에는 의존하지 않고 비즈니스 로직을 관리하고자, features 레이어의 model 영역은 React Hook 대신 순수 JavaScript로 작성하도록 기준을 세웠습니다. 이를 통해 특정 라이브러리에 대한 의존도를 줄이는 데 집중했습니다.
4) Public API(배럴 파일) 제한적 사용
- CSR 기반 SPA 환경에서는 배럴 파일이 청크 분할‧생성에 방해가 되어 초기 렌더링 속도를 저해할 수 있다는 점을 확인하고, 공통 모듈에만 최소한으로 적용하였습니다.
위 방법을 채택한 배경과 이유
새로운 아키텍처를 고민하며, 아래 네 가지 핵심 원칙을 세웠습니다.
FSD는 역할에 따라 계층이 명확히 구분되고, 비즈니스 도메인 중심의 물리적 인접성까지 확보할 수 있는 점이 특히 매력적이었습니다. 이 모든 요구를 가장 균형 있게 충족하는 체계적이고 명확한 구조를 제공한다고 판단했습니다.
성과 및 기대 효과
-
의존성 감소와 응집도 향상
UI 코드가 비즈니스 로직이나 API 계층에 불필요하게 영향을 미치지 않는 계층구조 덕분에, 요구사항 변경 시에도 영향 범위를 명확하게 예측하고 안정적으로 관리할 수 있게 됐습니다. 또한 하위 계층은 파일이 변경되지 않아 해쉬값이 유지되므로 캐싱의 효율을 극대화 할 수 있었습니다.
-
역할과 책임이 명확한 협업 구조
app, shared와 같은 공통 모듈 담당자와 각 slice 담당자의 책임이 명확히 구분되어, 코드 충돌이나 반복적인 커뮤니케이션에 소요되는 비용이 크게 줄었습니다.
-
직관적인 코드 추적
파일명을 정확히 기억하지 못하더라도, 계층 구조와 폴더명만 보면 해당 모듈의 성격이나 도메인을 쉽게 짐작할 수 있어 전체적인 파일 탐색 시간이 대폭 단축되었고, 개발 생산성도 자연스럽게 올라갔습니다.
아쉬웠던 점 및 보완 방향
- 팀원 간 러닝커브 차이: 레이어 매핑 가이드를 제공했지만, 팀원별 경험 차이로 인해 초기 적응 과정에서 완전히 격차를 해소하지는 못했습니다. 앞으로는 페어 프로그래밍과 코드 리뷰를 꾸준히 진행해, 반복 학습을 통한 온보딩 품질 향상에 집중할 예정입니다.
- shared 레이어 비대화 및 빌드 성능 저하: shared 레이어의 비대화와 그로 인한 빌드 성능 저하 문제도 경험했습니다. 프로젝트 규모가 점차 커지면서 논리적 구분만으로는 shared 레이어가 점점 무거워졌고, 빌드와 배포 시간 역시 길어졌습니다. 단순한 구조적 분리만으로는 한계가 있다는 것을 절감했고, 도메인 간 물리적 독립성의 중요성을 실감할 수 있었습니다.
- Turborepo + MFE 아키텍처 도입: 이러한 한계를 넘어서는 방안으로 Turborepo 기반의 MFE 아키텍처 도입을 추진하고 있습니다. 이를 통해 도메인별로 독립적인 빌드와 배포가 가능해지고, 궁극적으로는 조직 전체의 확장성과 유지보수성을 크게 높일 계획입니다. 앞으로도 이러한 경험을 바탕으로 더 효율적인 협업 환경을 만들어 나가겠습니다.
4. 캐싱 및 서버 상태 관리 도입
문제 상황
- 동일 데이터에 대한 중복 API 요청: 레거시 시스템을 분석한 결과, 공통 코드나 호텔 정보 등이 페이지를 이동하거나 이벤트가 발생할 때마다 반복적으로 요청되고 있었습니다. 실제로 동일한 데이터에 대해서 1초에 약 6건 가량의 중복 요청이 쏟아졌고, 이로 인해 서버 부하가 커지고 클라이언트의 성능도 저하되는 문제가 확인되었습니다.
해결 방안
저는 단순히 데이터를 받아오는 수준을 넘어서, 확장 가능한 서버 상태 관리 필요성을 인식했습니다. 이에 TanStack Query를 도입했고, 아래와 같은 핵심 전략을 마련했습니다.
1) Query Key 관리
- createQueryKeys 유틸리티를 활용해 팩토리 패턴으로 쿼리 키를 일원화했습니다. 호텔 코드, 상세 ID, 언어 등 다양한 파라미터 조합에 따라 쿼리 키가 생성되도록 일관성 있게 관리함으로써, 휴먼 에러를 줄이고 각 모듈의 독립성도 높였습니다.
2) API 호출의 철저한 캡슐화
- 모든 API 요청을 FSD의 entities 레이어에 커스텀 훅으로 추상화하여, 중복된 코드 작성이 없도록 했습니다. 이를 통해 이미 받아온 데이터에 대해서는 추가 요청이 이뤄지지 않도록 원천적으로 차단했습니다.
3) 데이터 성격별 캐시 전략 수립
- 정적 데이터: 호텔 카탈로그나 환율처럼 거의 변하지 않는 정보는 staleTime: Infinity로 설정해 세션 내 재요청을 방지했습니다. 주기적 최신화가 필요한 경우엔 staleTime을 1시간으로 두고, refetchInterval 폴링을 병행했습니다.
- 동적 데이터: 예약 가능 여부나 실시간 가격처럼 자주 바뀌는 정보는 staleTime을 0 또는 아주 짧게 설정해 데이터의 신선도를 최대한 보장했습니다.
4) 렌더링 효율 극대화
- API 응답 중 꼭 필요한 필드만 select 옵션으로 구독해, 실제 데이터 변화가 있을 때만 리렌더링이 발생하도록 최적화했습니다.
위 방법을 채택한 배경과 이유
- 대규모 호텔 서비스에 적합한 확장성: SWR은 가볍고 직관적이라는 장점이 있지만, ‘지역 선택 → 호텔 조회 → 객실 및 가격 확인’으로 이어지는 호텔 도메인 특유의 복잡하게 얽힌 종속 쿼리를 다루기에는 TanStack Query가 훨씬 더 강력하고 적합하다고 판단했습니다.
- 정교한 캐시 무효화: 예약이나 취소처럼 데이터가 수정되는 시점마다 관련 쿼리 키만 세밀하게 무효화해, 서버와 클라이언트 데이터가 즉시 동기화되도록 할 수 있다는 점도 TanStack Query의 큰 강점이었습니다.
- 손쉬운 디버깅: 전용 DevTools를 통해 캐시 상태와 쿼리 흐름을 시각적으로 확인할 수 있어, 복잡한 연관관계도 한눈에 파악하고 신속하게 문제를 진단할 수 있었습니다.
성과 및 기대 효과
-
서버 트래픽 감소
캐싱과 중복 요청 차단 덕분에 API 호출 수가 기존 대비 평균 6배 이상 줄었습니다. 이에 따라 서버 자원을 효율적으로 사용하게 되었고, 운영 비용 절감도 기대할 수 있었습니다.
-
UX 개선
페이지를 이동할 때 이미 캐시에 저장된 데이터가 즉각적으로 화면에 노출되어, 사용자는 로딩 지연 없이 빠른 속도를 직접 체감할 수 있었습니다. 또한, Prefetching 기능과 결합하여 페이지 전환 속도를 크게 높이는 데에도 중요한 역할을 했습니다.
아쉬웠던 점 및 보완 방향
- 고급 기능의 적극적 활용 부족: 프로젝트 초기에는 주로 데이터 캐싱과 중복 요청 해소에 집중하다 보니, useSuspenseQuery 등 최신 기능들을 충분히 활용하지 못했습니다. 앞으로는 React의 Suspense와 ErrorBoundary를 더욱 유연하게 결합해 로딩과 에러 상태를 보다 선언적으로 관리하고, TanStack Query가 제공하는 다양한 고급 기능들도 깊이 있게 익혀 시스템의 완성도를 높이고자 합니다.
5. 공통 컴포넌트 가이드 및 Storybook 기반 CDD 환경 구축
문제 상황
- 공통 컴포넌트의 파편화: 기존에 개발된 공통 컴포넌트의 존재를 손쉽게 파악할 수 없어, 이미 있는 컴포넌트를 재활용하지 못하고 중복 구현하는 비효율이 반복적으로 발생했습니다.
- 문서 동기화 지연 및 온보딩 병목: 기존 PPT 기반 UI 가이드는 실코드의 업데이트 속도를 따라가지 못해 항상 최신 정보 제공이 어려웠습니다. 이 과정에서 문서 파일은 점점 커지고 배포도 번거로워져, 신규 개발자들이 온보딩할 때 필연적으로 병목현상이 생겼습니다.
- 단위 검증 체계 부재: 각 컴포넌트를 별도로 테스트할 환경이 없어, 작은 UI 수정도 전체 시스템 안정성을 예상할 수 없는 상태에서 반영될 수밖에 없었습니다. 그 결과, 의도치 않은 사이드 이펙트 리스크가 늘 내재돼 있었습니다.
해결 방안
Storybook 기반 독립 UI 개발환경 구축
- Controls 제공: 다양한 props 조합을 직접 UI 상에서 실시간으로 조작할 수 있게 해, 컴포넌트가 가진 여러 상태나 옵션 변화를 바로바로 확인할 수 있도록 했습니다.
- Code Snippet 활용: 복잡한 데이터 연동이나 마크업이 필요한 부분도, 별다른 추가 수정 없이 곧바로 앱에 붙여넣어 적용할 수 있도록 코드 스니펫을 제공했습니다.
- 엣지 케이스 시각화: 네트워크 지연, 에러, 데이터 부재 등 다양한 예외 상황을 별도의 story로 작성하여, 코드가 바뀌더라도 디자인 의도대로 제대로 동작하는지 한 번 더 확인할 수 있는 안전장치를 마련했습니다.
위 방법을 채택한 배경과 이유
- 백엔드에서 API 명세를 위해 Swagger가 필수인 것처럼, 프론트엔드에도 독립적인 UI 개발 환경과 실시간으로 동기화되는 가이드 문서가 반드시 필요하다고 느꼈습니다.
- 동시에 CDD(컴포넌트 주도 개발) 문화를 정착시키기에도 Storybook만큼 효율적이고 확장성 있는 도구는 없다고 판단하여 도입하게 되었습니다.
성과 및 기대효과
-
온보딩 시간 단축
컴포넌트를 눈에 띄게 파악할 수 있게 되면서 신규 인력의 Time to First PR이 무려 60%나 빨라졌습니다.
-
문서화 자동화
Storybook 내에서 실제 컴포넌트 코드와 가이드 문서가 항상 100% 동기화된 상태로 유지되며, 문서 최신화 이슈가 크게 해소되었습니다.
-
시스템 안정성 확보
UI를 독립된 환경에서 분리·테스트할 수 있어, 의도치 않은 사이드 이펙트 위험을 대폭 줄였습니다.
아쉬웠던 점 및 보완 방향
- DX(개발자 경험) 개선: Story 작성이 팀원들에게 또 하나의 부담으로 느껴졌다는 점이 아쉬웠습니다. 앞으로는 TSDoc이나 JSDoc 주석을 기반으로 Props 문서를 자동 추출(Storybook Docs)하고, CLI 기반 보일러플레이트 생성 스크립트도 도입해 반복 작업의 피로를 줄일 계획입니다.
- MSW(Mock Service Worker) 고도화: 기존에 단순 JSON Server나 Mock 파일을 사용하던 방식에서 벗어나, 네트워크 레이어 자체를 가로채는 MSW 도입으로 컴포넌트 내부 fetch/axios 코드를 따로 수정하지 않고도 실제 프로덕션 환경과 유사하게 개발·테스트하려고 합니다.
- 테스트 자동화 파이프라인 구축: 기존에는 시각적으로 일일이 확인해야 했던 검증 과정에 한계가 있어, 앞으로는 Playwright와 같은 테스트 자동화 도구를 활용해 E2E 테스트부터 VRT(시각적 회귀 테스트)까지 자동화할 계획입니다.